Hur ordnar man en mängd oorganiserade geologiska data till en meningsfull struktur (taxonomi), dvs hur systematiserar man bokstavligt talat ett berg av geodata i ett överskådligt klassifikationssystem (taxonomiskt system). En framkomlig väg kan vara att söka hjälp i den s k klusteranalysen, en analysmetod som beskrevs redan under 1930-talet (Tryon, R. C.: Cluster Analysis. Ann Arbor, MI: Edwards Brothers 1939). Klusteranalys har framgångsrikt applicerats för en rad olika forskningsfält, allt från arkeologi och biologi till medicinens domäner. I en utomordentligt läsvärd bok har J.A. Hartigan sammanställt resultat från en mängd publicerade studier från klusteranalysens olika applikationsområden (Hartigan, J. A.: Clustering algorithms. New York: Wiley 1975).
För amatörgeologen finns en mängd tillämpningsområden för vilka ett starkt behov finns att inordna osystematiserade data till en överskådlig enhet. Vi skall i föreliggande kortfattade artikel exemplifiera klusteranalysens användbarhet med en studie av geodata hämtade från det paleontologiska fältet.
Antag att vi från en geologisk lokal provtagit ett antal fossil. Hemma vid vårt arbetsbord har en preliminär genomgång av det insamlade materialet visat att fossilen ifråga kännetecknas av ett visst antal typkaraktärer (exempelvis skal-längd, skal-bredd, skal-tjocklek, antal taggutskott etc). Vi sammanställer våra iakttagelser i tabellform enligt följande:
Tabell över 10 fossilexemplars 10 typkaraktärer (KAR = typkaraktär; SP = specimen = exemplar)
KAR1 KAR2 KAR3 KAR4 KAR5 KAR6 KAR7 KAR8 KAR9 KAR10 SP 1 74 12 79 27 105 26 7 48 31 39 SP 2 69 12 74 24 120 24 7 44 29 66 SP 3 71 11 72 24 130 24 8 44 30 32 SP 4 82 14 86 30 115 25 8 47 35 40 SP 5 77 13 81 30 110 27 9 50 34 37 SP 6 67 11 72 22 115 24 7 46 28 33 SP 7 58 10 62 20 110 21 6 40 25 29 SP 8 59 9 62 19 100 20 5 36 25 27 SP 9 78 15 80 28 95 27 9 50 33 38 SP 10 65 10 70 22 105 22 5 41 28 32 Vi specificerar ej konkret här vad de tio typkaraktärerna och deras numeriska värden egentligen står för, utan betecknar dem endast KAR 1, KAR 2 etc. I avsikt att ej onödigtvis tynga framställningen har vi valt att bygga vår fiktiva studie på ett mycket begränsat material (endast tio fossila exemplar, vardera karakteriserat av tio typkaraktärer). Att klassificera ett material bestående av så få data kan givetvis låta sig göras utan klusteranalys, men skulle vårt material omfatta hundratals eller kanske tusentals exemplar med ett stort antal typkaraktärer, ja då kommer vi upptäcka klusteranalysens verkliga styrka.
Vad klusteranalysen nu gör är att länka samman objekt ( i vårt fall de aktuella fossilexemplaren) till grupper eller kluster (eng. clusters) genom att jämföra objekten med varandra.. Objekt, alltså i vårt fall fossilexemplar, med minsta s k linkage distance, dvs med lägsta "länkavstånd" avseende olikartade karaktärer, samlas till samma kluster. Som ett parentetiskt exempel kan nämnas att människan, som i likhet med apan, hunden eller katten tillhör gruppen däggdjur, har exempelvis fler gemensamma typkaraktärer med apan än med hunden och katten. Således kommer i ett klassifikationsschema människan och apan erhålla ett lågt länkavstånd, dvs de kommer att inordnas i ett kluster för sig, under det att hund och katt kommer att tillhöra ett annat kluster.
Låt oss nu se om våra tio fossilexemplar verkligen är helt olika varandra och sålunda skall organiseras i tio separata kluster.
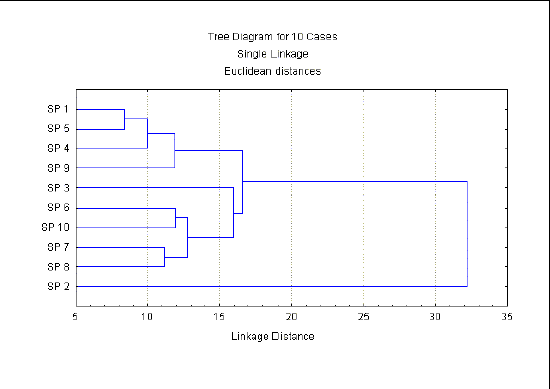
Av tabellen nedan finner vi att klusteranalysen faktiskt har funnit att vissa typkaraktärer för vissa fossilexemplar är förhållandevis lika varandra. Tabellens första kolumn redovisar det s k linkage distance, dvs länkavståndet, ett mått som innebär att ju lägre dess numeriska värde är desto mindre är olikheterna mellan de länkade objekten ifråga. Första raden i tabellen visar de fossilexemplar som är mest lika varandra med avseende på de ingående typkaraktärerna. I vårt fall finner vi sålunda att specimen 1 och 5 (dvs fossilexemplar 1 och 5) är nära "besläktade" med varandra och kan därför i ett klassifikationsschema (taxonomiskt schema) inordnas i ett separat kluster.
8,366600 SP 1 SP 5 10,00000 SP 1 SP 5 SP 4 11,18034 SP 7 SP 8 11,87434 SP 1 SP 5 SP 4 SP 9 11,95826 SP 6 SP 10 12,76715 SP 6 SP 10 SP 7 SP 8 15,96872 SP 3 SP 6 SP 10 SP 7 SP 8 16,64332 SP 1 SP 5 SP 4 SP 9 SP 3 SP 6 SP 10 SP 7 SP 8 32,20248 SP 1 SP 5 SP 4 SP 9 SP 3 SP 6 SP 10 SP 7 SP 8 SP 2 Innan vi diskuterar fortsättningen av ovan tabell skall skall vi överföra tabellens värden till ett s k klusterdiagram i avsikt erhålla en bättre visualisering av tabellens struktur:
Fig 1
Grafens x-axel redovisar de aktuella värdena för länkavståndet under det att y-axeln redovisar de aktuella fossilexemplaren. Vi ser här hur objekten SP 1 och SP 5 bildar ett tydligt avgränsat kluster (se även tabellen ovan, rad 1). Detta kluster har lägsta länkavstånd (8,3666), dvs detta kluster länkar samman objekt som har största likhet med varandra - eller som det också uttrycks har minsta olikhet med varandra. Närmast likt objekten SP 1 och SP 5 är SP 4 (länkavstånd = 10,0), som på grafen länkats till SP 1 och SP 5 (se tabellen ovan, rad 2). Därefter (se tabellen, rad 3) följer SP 7 och SP 8 (länkavstånd = 11,1803), som bildar ett eget kluster. Läsaren kan nu själv följa vidare grafens övriga objekt, hur och i vilken grad de är relaterade till varandra.
Som nämnts inledningsvis kommer klusteranalysen till sin verkliga rätt när ett mycket stort datamaterial föreligger. Den intresserade amatörgeologen har säkert många gånger kämpat förgäves med just ett sådant stort datamaterial och kanske gäckats i sina försök att bringa ordning i det oorganiserade och osystematiska materialet. Klusteranalysen kan kanske vara lösningen på hans problem och värd att pröva. För den intresserade finns många datorstödda klusteranalyssystem att köpa, och läsaren föreslås själv botanisera ute på nätet och via någon sökmotor leta efter företag som tillhandahåller statistiska program.
© 1999 Göran Kjellström
©2001-
GeoNord ![]()